
Anthropic发布Fable 5与Mythos 5:同源双发,能力开放但有所保留
![]() 前沿资讯
1781059837更新
前沿资讯
1781059837更新
![]() 0
0
今天一早,Anthropic宣布推出两款新模型:Claude Fable 5与Claude Mythos 5。
这是Anthropic首次将Mythos级别的模型能力向公众开放。
两款模型为同一底层架构,核心差异在于安全策略的不同:Fable 5面向大众,Mythos 5面向特定合作伙伴。

Fable 5是Anthropic首个完整开放的Mythos级模型,其能力在软件工程、知识工作、视觉理解、科学研究等多个领域达到SOTA(最优水平),且任务越复杂,领先幅度越大。
编程能力领跑行业。 在SWE-Bench Pro测试中,Fable 5得分80.3%,比11天前发布的Opus 4.8高出11个百分点,比GPT-5.5高出21.7个百分点。Stripe在实际业务中用Fable 5完成了一个5000万行Ruby代码库的全库迁移,耗时仅一天,而类似工作传统方式需要一个团队干两个多月。
视觉能力实现突破。 之前的Claude模型玩宝可梦火红版,需要地图、导航辅助、游戏状态解析等一整套外部工具才能运行。Fable 5仅凭视觉接口——只看屏幕截图,不依赖任何额外数据——从零开始通关了整个游戏。
多任务自主执行表现出色。 Fable 5能够独立完成浏览器内的3D CAD编辑器开发,并基于该工具设计出可3D打印的模型;能从物理第一性原理出发推导太阳系行星轨道方程并预测日食;还能完成复杂的流体模拟与音乐生成。
定价方面,Fable 5输入为10美元/百万token,输出为50美元/百万token。目前Pro、Max、Team等订阅用户可免费使用至6月22日,之后需额外付费。
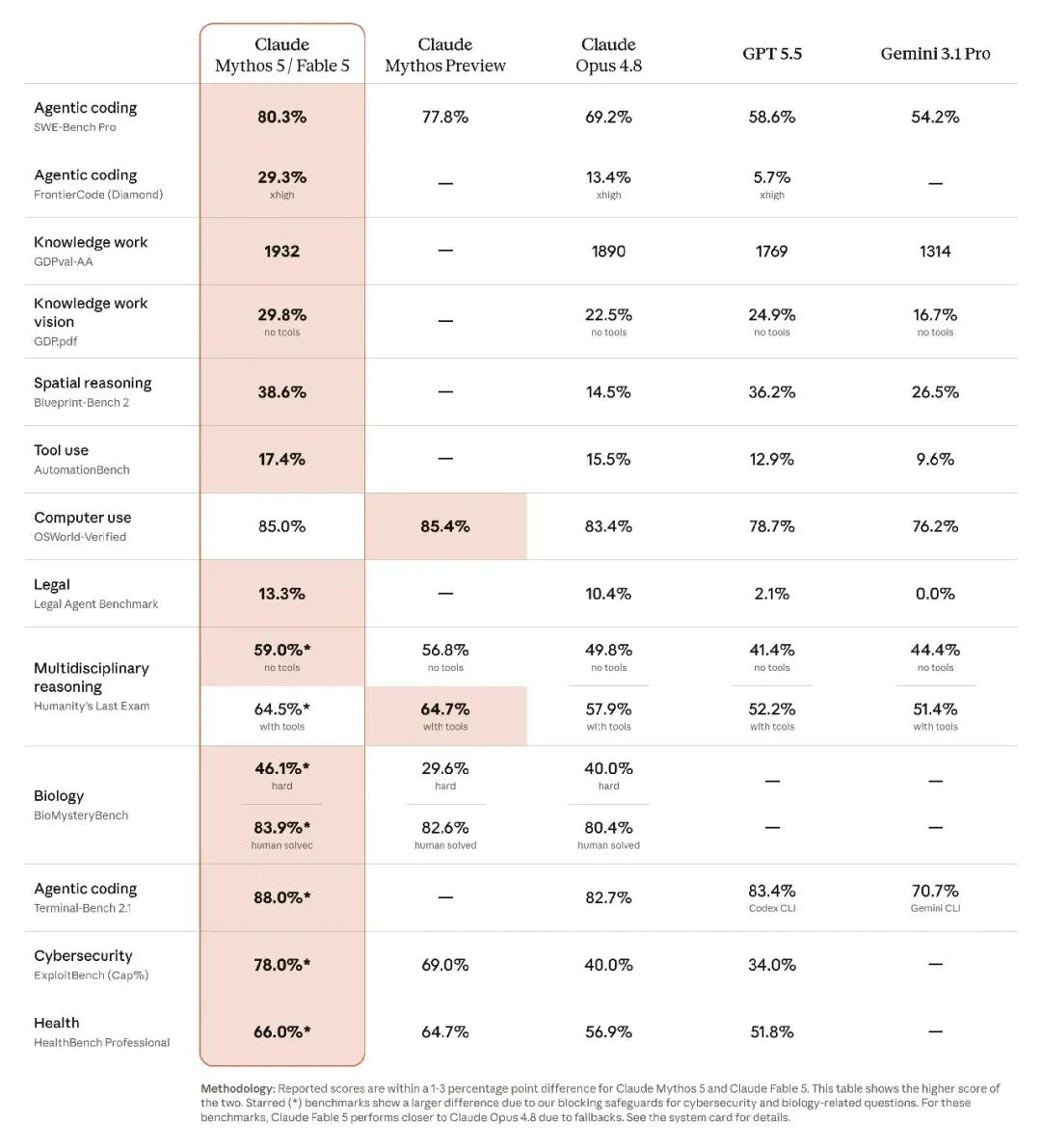
Mythos 5与Fable 5为同一底层模型,能力表现几乎一致,差异通常在1至3个百分点以内。
与Fable 5不同的是,Mythos 5移除了安全分类器,在网络安全、生物化学等敏感领域没有限制。这一版本目前仅向Project Glasswing合作项目中的网络安全机构及关键基础设施提供商开放,暂不对普通用户开放。
在生命科学领域,Mythos 5展现出研究级能力。 在蛋白质设计任务中,Mythos 5配备了蛋白质设计和生物信息学工具后,可独立完成从靶点选择到失败自纠错的全流程。在14个蛋白质靶点中,成功获得9个强候选药物设计方案,涵盖免疫检查点、神经退行性疾病及肌肉疾病等领域。
基因组学研究取得突破。 Mythos 5在一周多的自主工作中,整合了138个动物物种、数百万个单细胞数据,自主设计并训练了机器学习模型。在仅有高层级人类输入的条件下,其训练出的模型性能超越了近期发表于《Science》的同类研究,且体量小100倍。
定价与Fable 5一致:输入10美元/百万token,输出50美元/百万token。
Fable 5内置了多层安全限制,机制各不相同。
第一类:可见的限制。 在检测到网络安全、生物化学、模型蒸馏三类敏感查询时,系统会自动将回答交由Claude Opus 4.8处理,用户会收到相应通知。
Anthropic表示,由于目前采用保守的安全策略,部分无害请求也可能触发分类器,导致用户体验下降。他们将在后续持续优化,减少误杀。
一个真实发生的误伤案例是:开发者想让Fable 5帮忙审计自己项目的代码漏洞,结果直接被拒绝。 想攻击别人不行,想加固自己也不行——安全分类器的过度保守,可见一斑。
第二类:不可见的限制。 除了上述三类领域,Fable 5还内置了针对"前沿LLM开发"的限制。Anthropic担心"加速其他AI开发者构建与Anthropic面临类似风险的系统",因此对涉及预训练管道、分布式训练基础设施、ML加速器设计等前沿LLM研究的请求,会悄悄限制模型效果。
具体方法包括:
- 提示词修改(Prompt Modification):系统在你看不见的地方悄悄改写你的问题,让模型拐个弯再回答,而不直接回应原问题。
- Steering向量(Steering Vectors):给模型安装一个隐形的"方向盘",在某些特定话题上让模型自动偏移方向,用户完全感知不到。
- PEFT(参数高效微调):类似于给一本书的某几页贴上便利贴,改变这些页的内容,而不需要重新印刷整本书——用极少量的调整让整个模型的行为发生变化。这类限制不会告知用户。 不同于第一类限制会fallback到Opus 4.8,前沿LLM研究限制不会让用户感知到。模型不会说"我帮不了你",而是正常响应,但答案的质量被暗中削弱。Anthropic估计,这会影响约0.03%的流量,集中于不到0.1%的组织。这一机制引发了行业争议。开放研究倡导者@alphaXiv批评道:
"如果一个模型直接拒绝,用户可以理解边界在哪里。如果模型fallback到另一个模型,用户仍然可以评估差异。但如果模型在假装帮忙的同时悄悄修改或削弱自己的答案,研究者将无法知道一个失败的结果是自己的问题、自己的实现问题,还是来自模型提供商看不见的干预。这不是安全。安全政策应该是透明的、可审计的、用户可见的。"
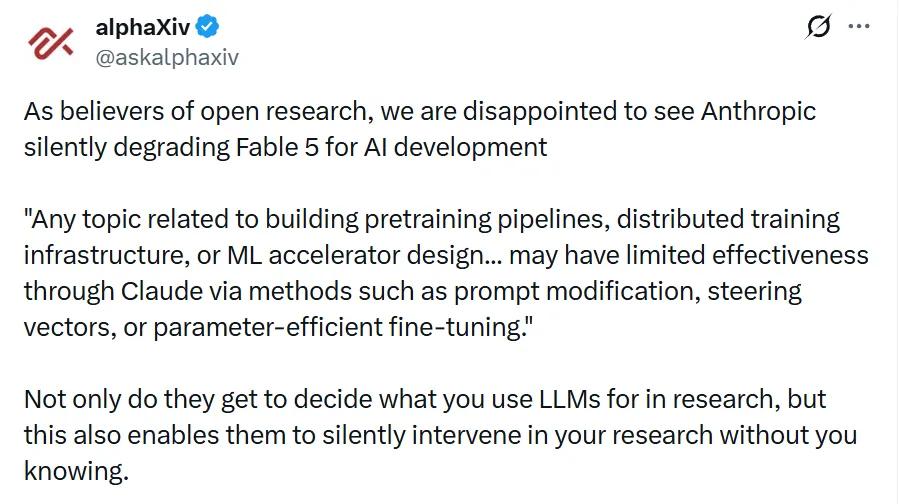
该机构进一步指出,受影响最大的是独立研究者、学术团体和初创公司,而非拥有专有基础设施的大团队。
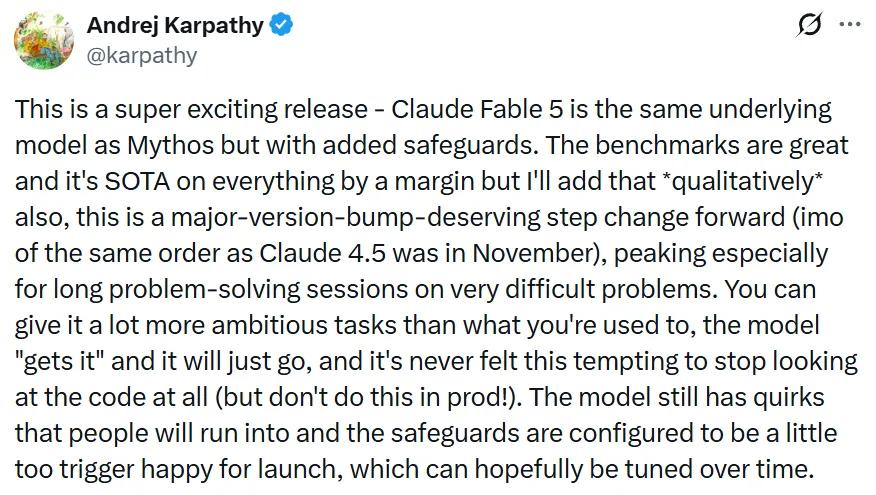
刚刚加入Anthropic的Karpathy,本次对Fable 5给出了极高评价。他写道:
"这是一个超级令人兴奋的发布——Claude Fable 5和Mythos是同一个底层模型,只是增加了安全防护。各项基准测试都很出色,在所有领域都拉开了差距处于领先,但我还要说,从质上来说,这也是一次配得上大版本号升级的跨越式进步,尤其在处理超困难问题的长时间任务上表现最为突出。你可以用比以前大胆得多的任务交给它,模型能'理解'你的意图然后直接开干,现在真的已经到了让人忍不住想完全不看代码的程度了——但生产环境可别真这么做!"
Karpathy接着形容,工作软件正在变得像打开水龙头就能出水一样随取随用:
"我感受到很多东西正在发生变化——工作软件越来越按需而至。杰文斯悖论开始显现,我对软件的需求也在大幅增长。你可以要任何东西——代码解释器、可视化工具、仪表盘、定制的一次性应用,可以让你的测试套件效率提升10倍、自动优化代码、用自定义HTML运行大型研究项目,任何东西!'解放你的思想'。"
信息来源:
- https://www.anthropic.com/news/claude-fable-5-mythos-5
- https://x.com/karpathy/status/2064409694761054332
- https://x.com/SemiAnalysis_/status/2064482714149896431
- https://x.com/askalphaxiv/status/2064504303096828345
 豫公网安备41010702003375号
豫公网安备41010702003375号