
具身思维链(ECoT)推理技术,赋予机器人“具身推理”能力
![]() 前沿资讯
1721441768更新
前沿资讯
1721441768更新
![]() 0
0
在人工智能领域,大型语言模型(LLMs)通过“思维链”(Chain-of-Thought, CoT)提示技术,展现出了解决复杂问题的卓越能力。这种技术指导模型将解决方案分解为具体步骤,从而实现更高效的推理过程。如今,研究人员正致力于探索这一技术是否同样能够提升机器人基础模型的性能。

来自加州大学伯克利分校、华沙大学和斯坦福大学的研究人员在他们的新论文中提出了这一问题,并介绍了“具身思维链推理”(Embodied Chain-of-Thought Reasoning, ECoT)的概念。ECoT是一种为视觉-语言-动作模型(Vision-Language-Action models, VLAs)设计的推理技术,通过使机器人在采取行动前对任务、子任务及其环境进行全面推理,从而增强其决策能力。
机器人控制策略的核心目标是使机器人能够自主执行复杂任务。尽管在开发端到端控制模型方面取得了显著进展,但这些模型在面对需要推理和规划的新情况时,往往表现不佳。为此,视觉-语言-动作模型(VLAs)应运而生,它们基于预训练的大型视觉-语言模型(VLMs),将图像观察和自然语言指令映射到机器人动作。VLAs在通用机器人策略方面取得了最先进的性能,并显示出对新对象和场景的显著泛化能力。例如,开源项目OpenVLA和谷歌DeepMind的RT-X-2都是这一领域的杰出代表。
尽管VLAs在某些方面表现出色,但它们在推理能力上仍显不足。它们学习从观察到动作的直接映射,缺乏中间推理步骤。为了解决这一问题,研究人员提出了将思维链推理引入VLAs的想法。通过生成中间步骤,LLMs能够更好地映射问题不同部分之间的关系,并提出更准确的解决方案。研究人员假设,通过训练VLAs以文本形式推理他们的计划、环境和动作,可以显著提升其性能。
然而,将CoT技术直接应用于机器人领域并非易事。首先,VLAs依赖的开源VLMs在推理能力上不如用于语言应用的大型LLMs。其次,机器人任务不仅需要对任务本身进行推理,还需要对环境和机器人自身的状态进行推理。因此,仅将任务分解为子任务是不够的,VLAs必须将他们的推理基于对环境的感知,以做出关于移动和操纵的明智决策。正如研究人员所言:“简单来说,我们需要VLAs不仅要‘仔细思考’,还要‘仔细观察’。”
为了克服这些挑战,研究人员开发了具身思维链(ECoT)推理技术。ECoT使机器人能够以一种基于他们对环境感知的方式推理他们的行动。ECoT结合了关于任务和子任务的语义推理以及关于环境和机器人状态的“具身”推理。这包括预测对象边界框、理解空间关系以及推理机器人可用动作,也称为“原语”,如何帮助实现目标。
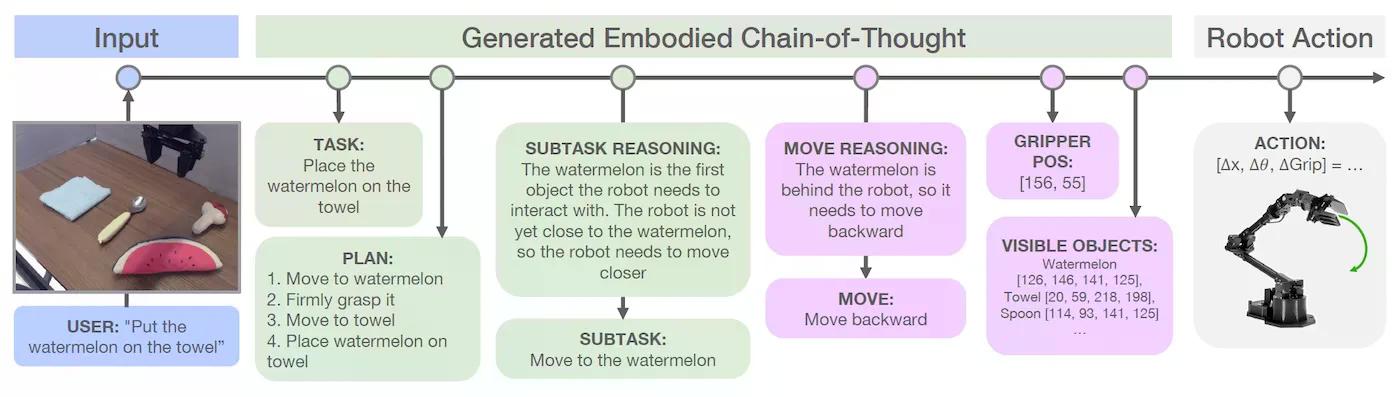
为了使VLA模型能够进行推理,研究人员创建了一个流程来生成合成训练数据,以训练VLAs进行ECoT推理。该过程涉及使用预训练的对象检测器、LLMs和VLMs来注释现有的机器人数据集,这些信息可以用于推理。然后,他们使用谷歌的Gemini模型生成完成任务的最终推理链。模型首先将给定的指令重新表述为更详细的形式,然后概述了完成主要目标所需的一系列子任务。通过分析环境和机器人的当前状态,模型确定了要专注的具体子任务。模型生成一个与所选子任务对齐的自然语言命令(例如,“向左移动”,“抓住物体”),并预测重要元素的像素位置,如机器人的夹持器和场景中对象的边界框。
 豫公网安备41010702003375号
豫公网安备41010702003375号