
大模型训练闭目养神就行?Meta:每三小时都要处理意外故障
![]() 前沿资讯
1722245438更新
前沿资讯
1722245438更新
![]() 0
0
最近,Meta发布了一份报告,揭示了Llama 3 405B模型在16384个英伟达H100 80GB GPU集群上进行训练时遇到的问题:在54天的训练期间,集群平均每三小时遇到一次意外故障,总计419次,其中GPU或其搭载的HBM3内存是导致故障的主要原因。

正如超级计算机领域的一句老话所言,大规模系统的运行中,故障是唯一确定的事情。超级计算机是极其复杂的设备,它们使用成千上万的处理器、数十万个其他芯片和数千公里的电缆。在这样的超级计算机中,每几小时出现故障是常态,而开发者的主要任务是确保系统能够持续运行,不受这些局部故障的影响。
在Llama 3的训练过程中,16384个GPU的规模和同步性使得系统很容易受到故障的影响。如果故障没有得到适当的缓解,单个GPU的故障就可能干扰整个训练任务,甚至需要重新启动。在这个情况下,Llama 3团队还是设法保持了超过90%的有效训练时间。
在54天的预训练期间,共记录了466次作业中断,其中47次是计划内的,而419次是意外的。计划内的中断是由于自动化维护,而意外的中断大多源于硬件问题。在这些意外中断中,GPU问题占据了58.7%,只有三起事件需要大量的手动干预,其余的都由系统自动化处理。419次意外中断,有30.1%是由各种GPU故障引起的,包括NVLink故障,而17.2%是由HBM3内存故障引起的。考虑到英伟达H100 GPU的高功耗和热应力,这种情况并不令人意外。有趣的是,在这段时间内,只有两个CPU发生了故障。
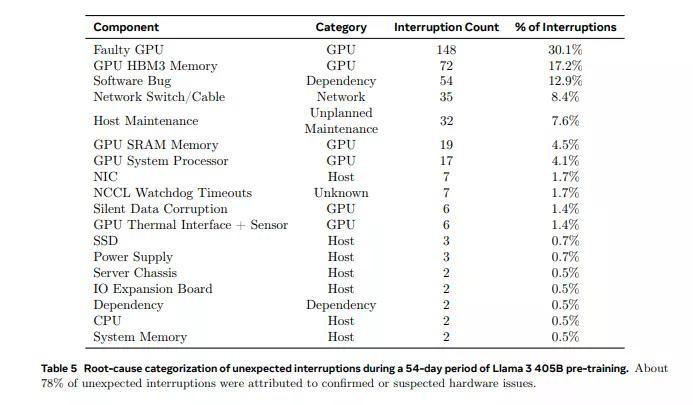
除了GPU,41.3%的意外中断还涉及到软件错误、网络电缆和网络适配器等多种因素。为了提高效率,Meta的团队采取了一系列措施,包括缩短作业启动和检查点时间,以及开发专有的诊断工具。PyTorch的NCCL飞行记录器被用于快速诊断、解决挂起和性能问题,尤其是与NCCLX相关的问题。NCCLX在故障检测和定位中发挥了关键作用,特别是在处理NVLink和RoCE相关问题时。通过与PyTorch的集成,它能够监控和自动超时由NVLink故障引起的通信停滞。此外,通过使用专门的工具,团队能够识别并解决拖后GPU的问题,这些GPU可能会减慢数千个其他GPU的速度,从而确保了整体训练效率的维持。
环境因素,如中午的温度波动,也对训练性能产生了影响,导致了1-2%的吞吐量变化。GPU的动态电压和频率调整受到这些温度变化的影响。同时,数万个GPU的同时功耗变化也给数据中心的电网带来了压力,这些波动有时在数十兆瓦,考验着电网的极限。
由以上的报告我们可以看到,大模型训练不仅要应对硬件故障,还要考虑环境因素和电网压力。考虑到一个16384个GPU的集群在54天内就经历了419次故障,我们可以想象,马斯克xAI的集群规模扩大到10万块H100 GPU,运维人员该有多么的忙碌。
 豫公网安备41010702003375号
豫公网安备41010702003375号