
DeepMind 使用稀疏自动编码器( SAE)来解释大模型这个“黑匣子”
![]() 前沿资讯
1722305410更新
前沿资讯
1722305410更新
![]() 0
0
在深度学习和人工智能领域,大语言模型(LLMs)模型以其惊人的语言理解和生成能力,正在改变我们与机器交流的方式。然而,大语言模型通常被视为“黑匣子”,因为它们的内部工作原理对于外部观察者来说往往是不透明的。为了解决这个问题,DeepMind的研究团队一直在探索使用稀疏自动编码器(SAE)来解释和理解这些大模型的工作原理。
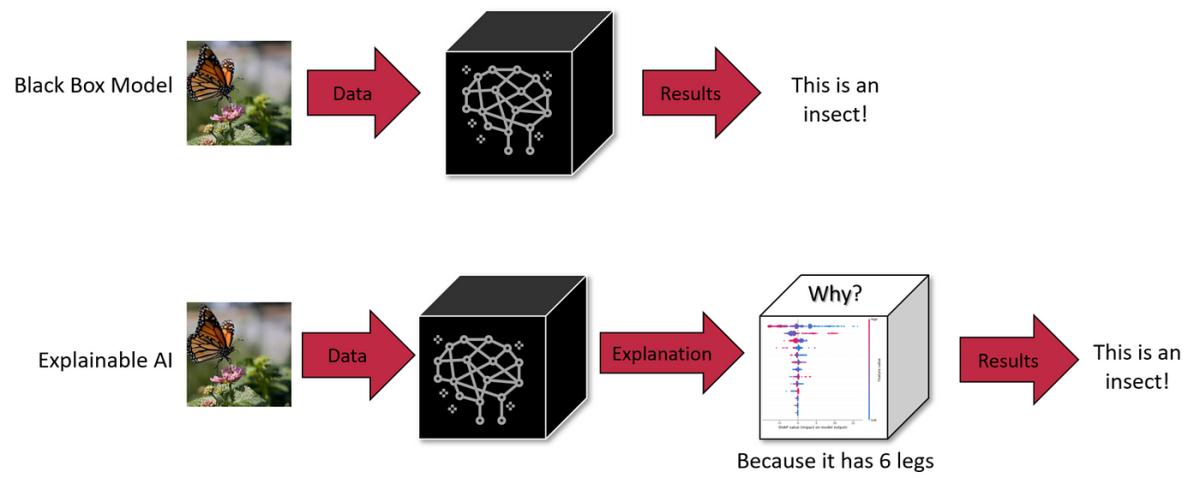
稀疏自动编码器是一种特殊的神经网络,它通过压缩和重建输入数据来工作。与传统的自动编码器不同,SAE在训练过程中引入了稀疏性惩罚,这促使网络生成稀疏的中间表示,即只有少数元素是非零的。这种稀疏性使得网络的中间表示更容易被人类理解和解释。
DeepMind的研究团队提出了一种名为“等信息窗口”的新颖压缩技术。这种方法通过将文本分割成多个区块,并确保每个区块压缩成相同的比特长度,从而实现了对神经压缩文本的有效学习。这种技术的优势在于,它不仅提高了训练和服务的效率,还使得处理长文本跨度变得更加容易。此外,通过这种方法训练的模型在易错性和推理速度基准上的表现远远超过了传统的字节级基准。
研究团队还深入探讨了稀疏自动编码器的工作原理。他们指出,SAE的灵感来自于神经科学中的稀疏编码假说,这一假说认为,世界上存在的许多变量是稀疏的,即大多数元素都是零或接近零。在大语言模型中,这种现象表现为神经元的组合表示,即多个神经元共同表示一个概念。通过使用SAE,研究人员可以开始将模型的计算分解为可理解的组件。
DeepMind还提出了一种名为门控稀疏自动编码器(Gated SAE)的新方法。这种方法通过分离“确定使用哪些方向”和“估计这些方向大小的功能”,解决了传统SAE中L1惩罚带来的收缩问题。这使得Gated SAE在保持可解释性的同时,只需要一半的触发特征即可实现相当的重建保真度。
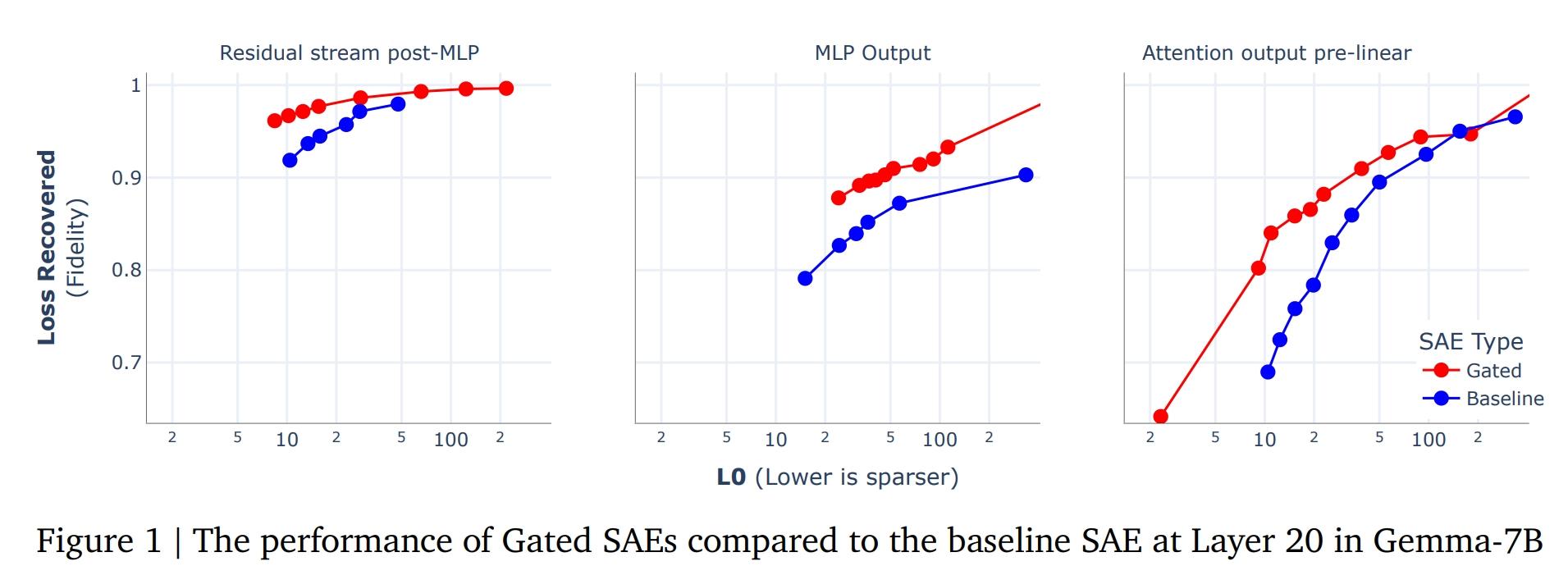
这些研究成果不仅为理解大语言模型提供了新的视角,也为进一步优化和改进这些模型提供了可能。通过稀疏自动编码器,研究人员可以更深入地了解模型的内部工作机制,从而为模型的未来发展提供指导。例如,通过将SAE应用于神经网络中的中间激活,研究人员可以更清楚地看到模型在处理语言时所依赖的关键信息。
此外,SAE的应用还扩展到了其他领域。例如,研究人员使用SAE来训练神经网络,以生成特征字典,这些特征字典可以用于解释生成的特征。通过这种方法,研究人员可以更好地理解模型的决策过程,并可能发现模型在处理特定任务时的潜在缺陷。
DeepMind在利用稀疏自动编码器来提高大语言模型的透明度和可解释性方面取得了显著的进展。这些研究成果不仅为理解这些复杂的模型提供了新的工具,也为未来的模型优化和改进提供了宝贵的见解。
 豫公网安备41010702003375号
豫公网安备41010702003375号