
DeepMind推出 GenRM 技术,通过创新的奖励模型提升推理能力
![]() 前沿资讯
1725677479更新
前沿资讯
1725677479更新
![]() 0
0
DeepMind推出了 GenRM 技术,这是一种生成式验证器,通过创新的奖励模型来提升 AI 的推理能力。这项技术的核心在于将验证过程重新定义为一个生成任务,就是将验证过程视为下一个标记预测问题,这样 AI 就能够更自然地利用其文本生成能力。
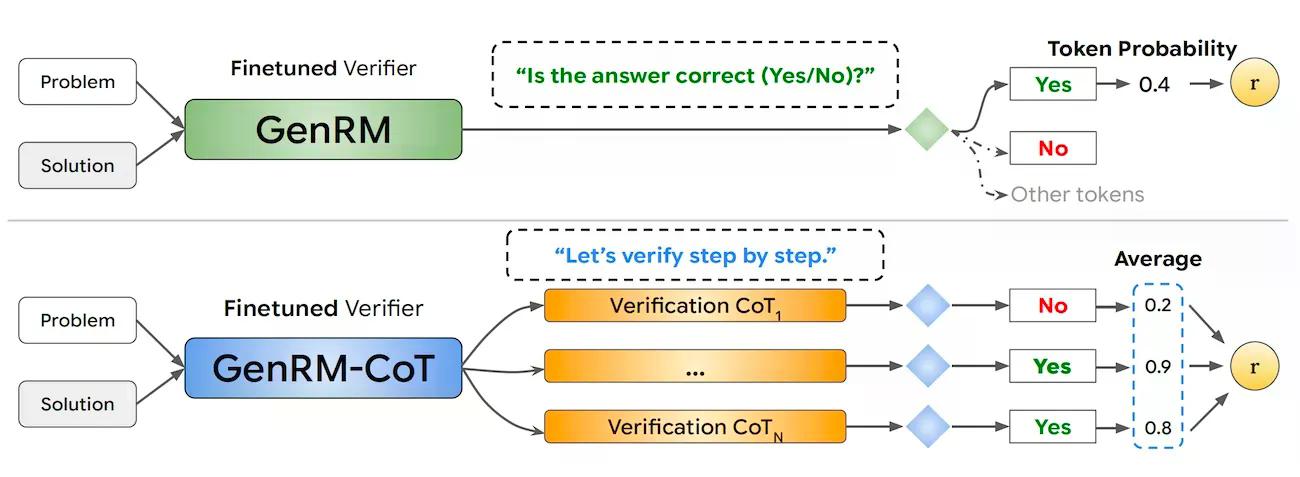
在 AI 领域,提高大语言模型性能的主流方法是 Best-of-N 模式。这种方法让大模型生成多个候选解决方案,然后由验证器对这些方案进行排序,选择出最佳答案。然而,传统的基于大模型的验证器通常被训练成判别分类器,这种方式主要是给每个解决方案打分,但却不能充分利用预训练大模型的文本生成能力,从而限制了验证器在复杂推理任务中的表现。
为了克服这一局限性,DeepMind 团队开发了 GenRM 技术。这种生成式验证器采用了一种新的训练方式,通过使用下一个 token 预测目标来训练验证器,使其不仅能验证候选方案,还能参与生成新的解决方案。这样的设计让 GenRM 在处理推理任务时具有显著优势。
GenRM 的优势之一是它能够无缝集成指令调整。可以根据给定的指令生成更符合预期的答案,从而提高了生成结果的准确性和相关性。另一个显著特点是它支持思维链(Chain-of-Thought, CoT)推理。这种推理方式能够更有效地处理链式推理问题,使得在复杂任务中的推理过程更加自然和连贯。
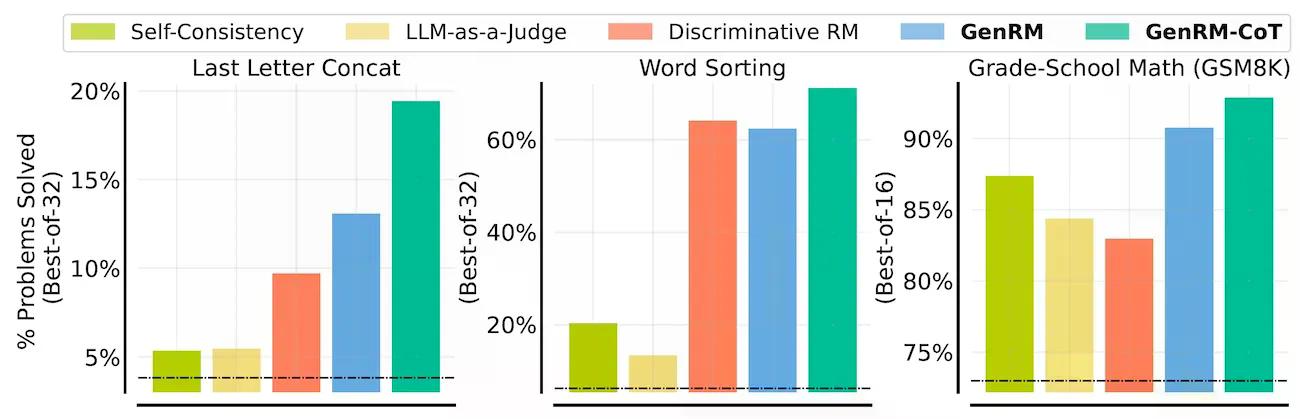
此外,GenRM 还能够利用额外的推理时间计算。通过多数投票机制,GenRM 能够利用额外的推理时间来进一步优化结果,确保最终答案的质量。在算法和小学数学推理任务中,使用基于 Gemma(GenRM 的一个实现)的验证器测试时,GenRM 的表现明显优于传统的判别式验证器和 LLM-as-a-Judge 验证器。通过使用 Best-of-N 方法解决问题,GenRM 的解决成功率提高了 16% 到 64%。
GenRM 技术的出现标志着 AI 奖励系统的一次重要演化。传统的分类奖励模型存在被操纵的风险,而 GenRM 的生成式奖励机制能够更好地防止模型出现欺诈行为。在未来,GenRM 技术可能会成为解决复杂问题的关键工具,帮助我们在各个行业中实现更高效、更准确的决策。
 豫公网安备41010702003375号
豫公网安备41010702003375号