
多模态指令遵循获最高分!开源多模态高性能模型新选择:Pixtral 12B
![]() 前沿资讯
1728545474更新
前沿资讯
1728545474更新
![]() 0
0
在多模态语言模型领域,对于能够同时理解图像和文本的大型模型的需求日益增长,这些模型在多种实际应用中展现出了巨大的潜力,例如在辅助决策、自动化客户服务以及提供多模态交互体验等方面。Mistral AI团队推出了Pixtral 12B,该模型旨在提供一个在多模态任务上表现出色的模型,同时保持对自然语言的深入理解,能够准确解析和生成语言文本。

Pixtral 12B的开发团队通过引入一个新的视觉编码器和对现有架构的改进,使得模型能够在不同分辨率和宽高比下处理图像,同时在长达128K tokens的上下文窗口中处理多张图像。这一创新使得Pixtral 12B在多模态基准测试中取得了领先性能,超越了许多更大参数规模的模型。
Pixtral 12B通过结合多模态解码器和视觉编码器来理解图像和文本。多模态解码器是建立在Mistral Nemo 12B的基础上,为了使Pixtral 12B能够处理图像,研究者们开发了一个新的视觉编码器,名为PixtralViT,这是一个从零开始训练的400百万参数视觉变换器,这个视觉编码器的设计目标是能够处理各种分辨率和宽高比的图像。
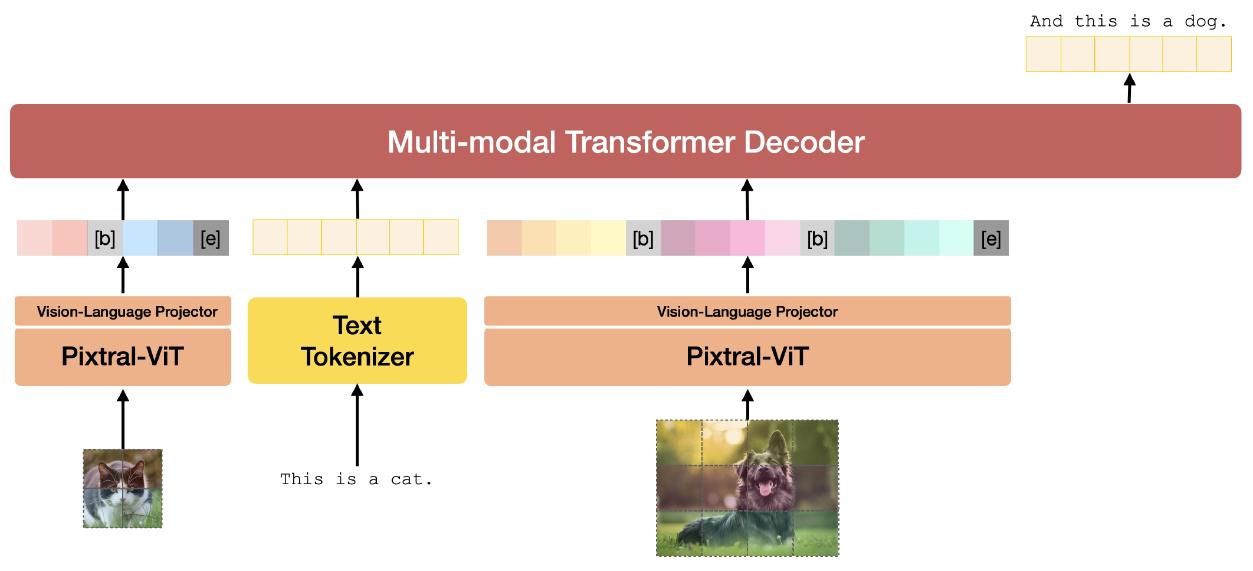
在多模态解码器中,图像tokens像文本tokens一样被处理,包括对所有tokens进行RoPE-1D位置编码。此外,解码器采用因果自注意力机制,这使得它能够平滑地处理多图像对话等复杂任务。这种架构的设计使得Pixtral 12B不仅能够灵活地处理不同大小和宽高比的图像,而且还能够保持对文本的深入理解,使其成为一个在多模态任务中表现出色的强大模型。
在评估Pixtral和基线模型时,研究者们发现,多模态语言模型的评估协议尚未标准化,设置中的小变化可能会显著改变某些模型的性能。为了解决这个问题,研究者们提供了在共同评估协议下重新评估视觉-语言模型的详细分析,并提出了“显式”提示,明确指定了参考答案所需的格式。此外,他们还分析了不同模型在灵活解析下的影响,并发布了评估代码和提示,以期建立公平和标准化的评估协议。
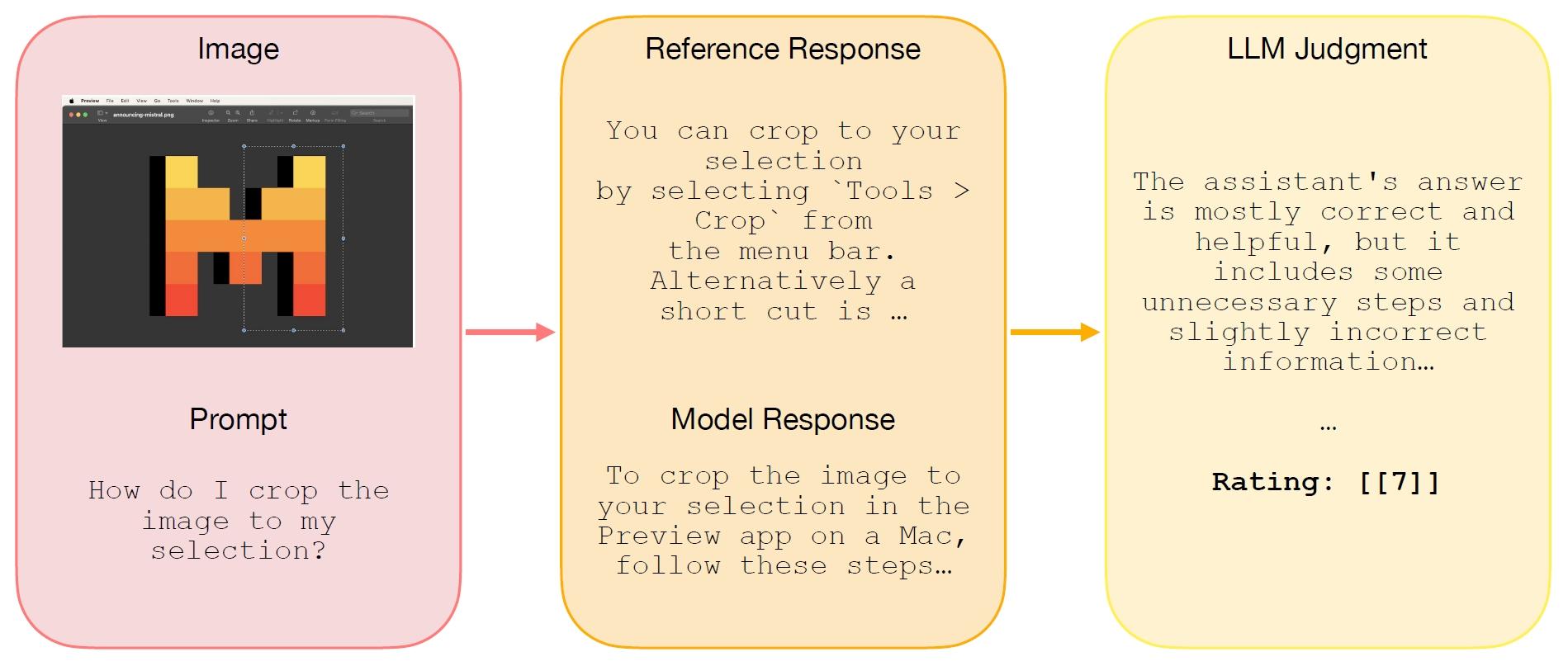
尽管当前的多模态基准测试主要评估模型在给定输入图像时的短形式或多项选择问题回答能力,但这些测试并没有完全捕捉到模型在实际使用案例中的实用性(例如,在多轮、长形式的助手设置中)。为了解决这个问题,研究者们开源了一个新的多模态、多轮评估:MM-MT-Bench。他们发现,在MM-MT-Bench上的表现与LMSys Vision Leaderboard上的ELO排名高度相关。
MM-MT-Bench的设计包含了92个对话,覆盖了五个类别的图像:图表(21个)、表格(19个)、PDF页面(24个)、图解(20个)和杂项(8个)。这些对话中包括69个单轮次对话、18个包含2轮次的对话、4个包含3轮次的对话和1个包含4轮次的对话。在评估模型时,会并行地查询模型对话的所有轮次,并为之前的轮次提供参考答案作为历史记录。每一轮都由独立的评价者根据1到10的评分标准独立评分,评分依据是模型提取信息的正确性(即提取的信息是否正确)和完整性(即模型回答是否涵盖了参考答案中提出的所有要点)。
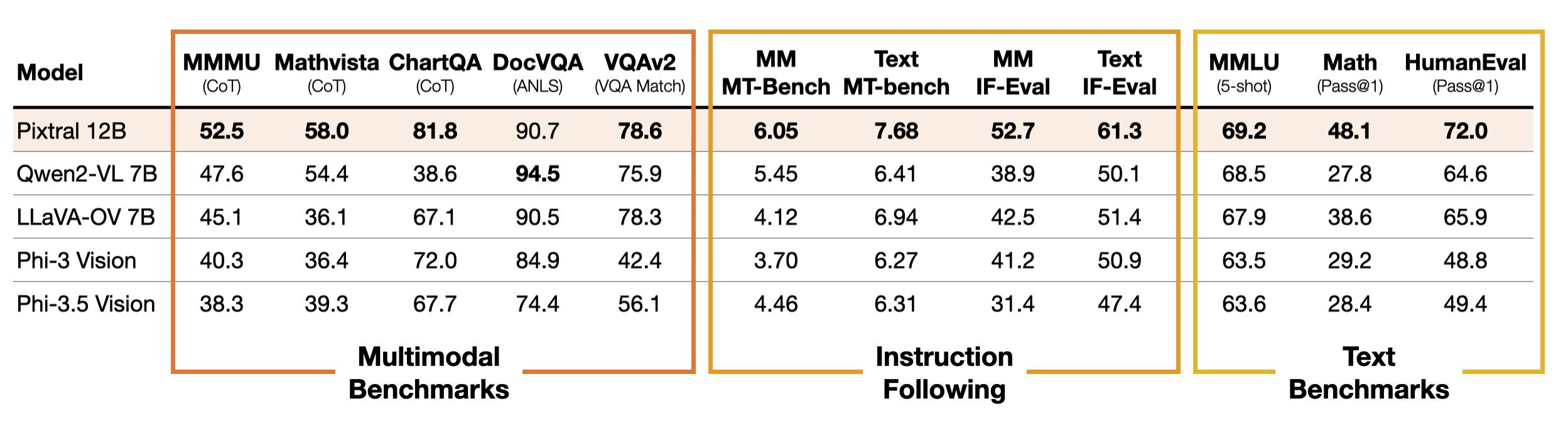
在与相似大小模型的比较中,Pixtral展现出了强大的多模态推理能力,同时没有牺牲仅文本推理性能。例如,它在流行的多模态基准测试如MMMU和MathVista上的表现超过了Qwen2-VL 7B和Llama-3.2 11B等模型,同时在流行的仅文本任务如MATH和HumanEval上超越了大多数开源模型。Pixtral甚至在多模态基准测试上超过了更大的模型,如Llama-3.2 90B,以及封闭模型,例如Claude-3 Haiku和Gemini-1.5 Flash 8B。
Pixtral 12B在Apache 2.0许可下发布,相关的网页、推理代码和评估代码的链接也已提供。
 豫公网安备41010702003375号
豫公网安备41010702003375号