
SuperCLUE发布中文多模态大模型基准10月榜单
![]() 前沿资讯
1728730454更新
前沿资讯
1728730454更新
![]() 0
0
自2024年以来,人工智能大模型技术和应用已经从文本扩展到了更多的模态,尤其是OpenAI发布的GPT-4系列多模态版本,在全球范围内掀起了多模态理解大模型的研发热潮。SuperCLUE团队在2024年8月发布了首个多模态测评基准SuperCLUE-V,并于今天发布了最新的测评报告。

SuperCLUE-V作为一个综合性测评基准,旨在为中文领域提供一个多模态大模型多维度能力评估的参考。测评体系包括基础能力和应用能力两大方向,涵盖了8个一级维度和30个二级维度。测评方法采用了细粒度评估方式,构建了专用测评集,并提供了详细的反馈信息。评估流程从模型与数据集的交互开始,模型需要基于提供的多模态信息进行理解和回应。评估标准包括理解准确性、回应相关性和推理深度等维度,打分规则结合了自动化定量评分与专家复核。
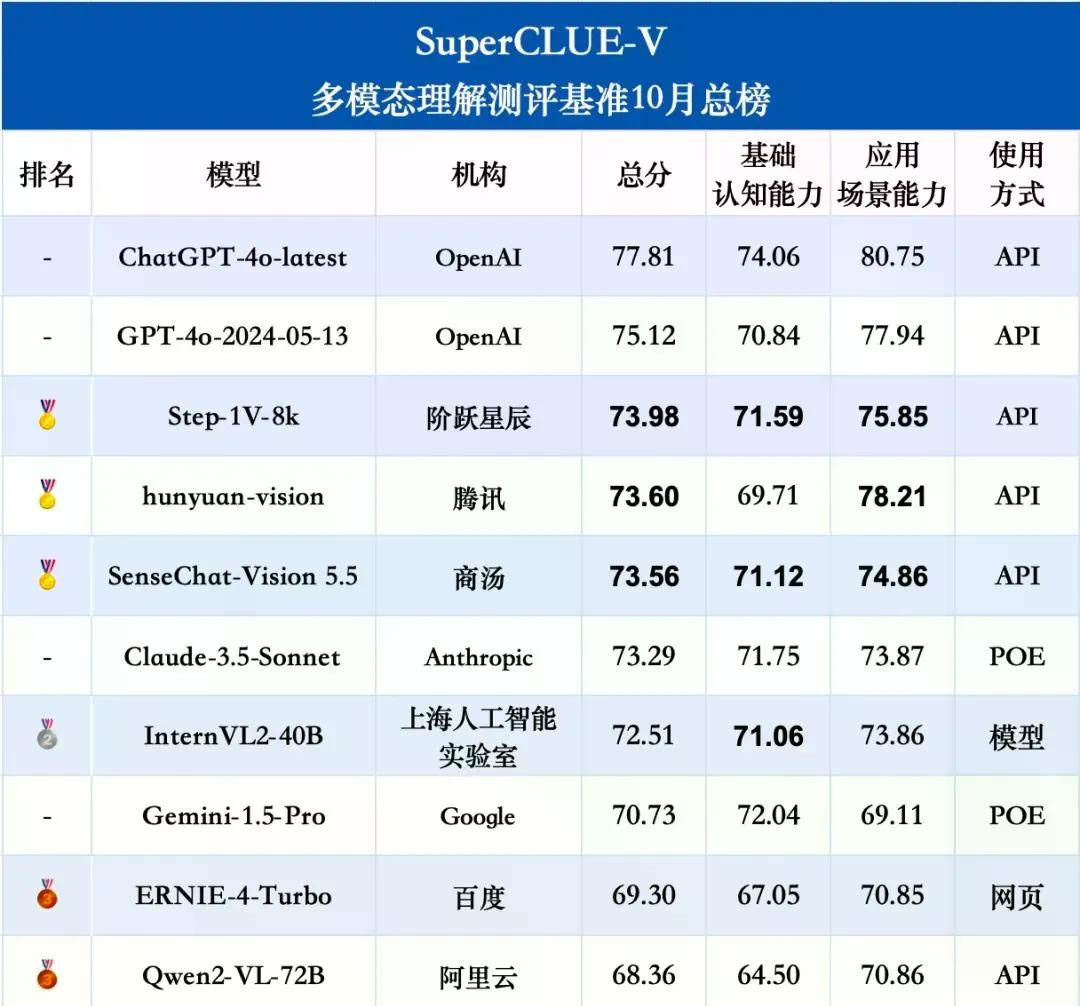
根据最新的评测报告内容,ChatGPT-4o-latest在多模态大模型的测评中表现突出,特别是在综合能力的评估上领跑。这款模型在多模态应用能力方面得分超过80分,在实际应用场景中的适配性和落地能力非常强。多模态应用能力涵盖了模型对不同模态信息的理解和处理能力,如视觉、语言等,以及这些信息如何被综合用于解决实际问题。
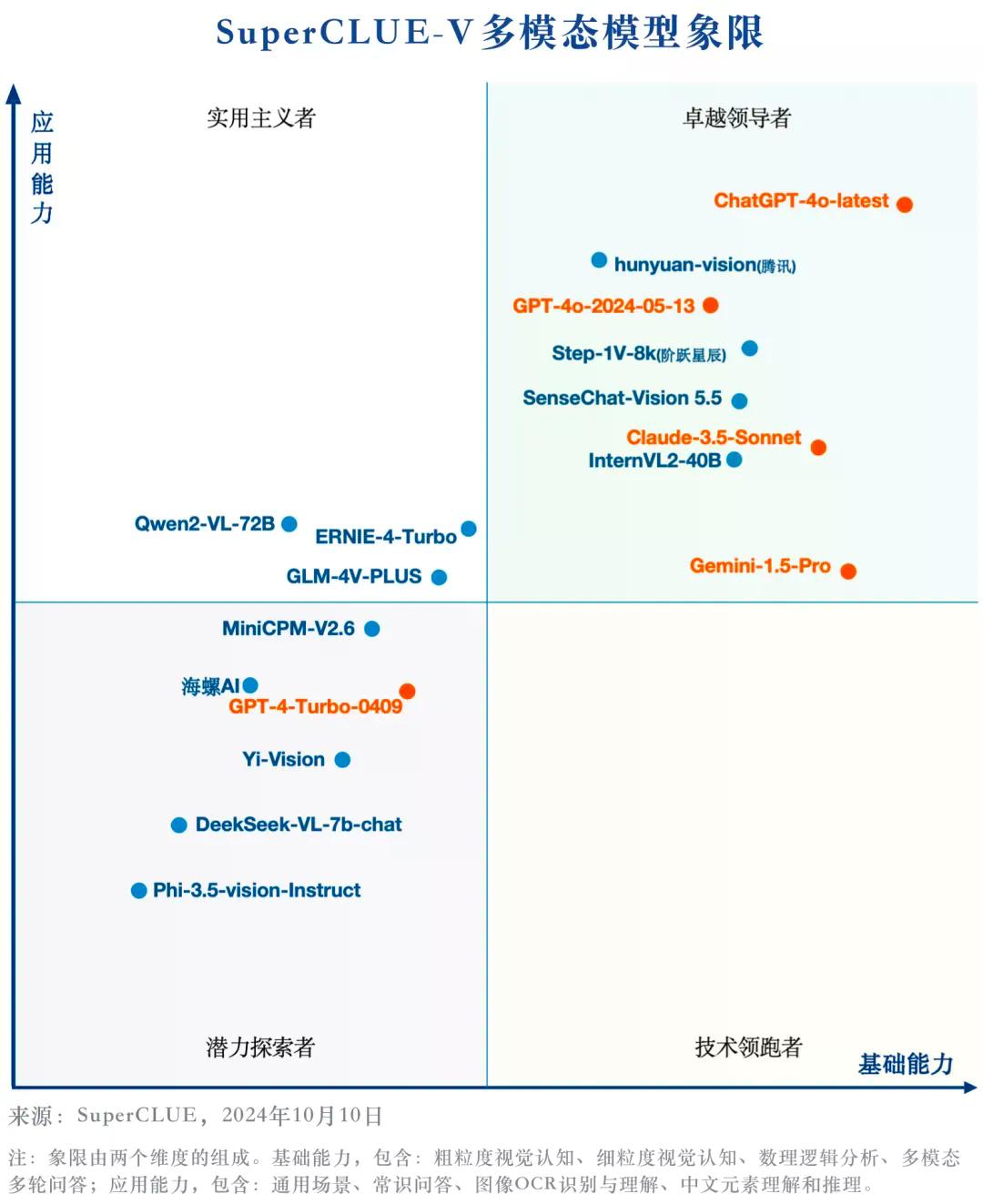
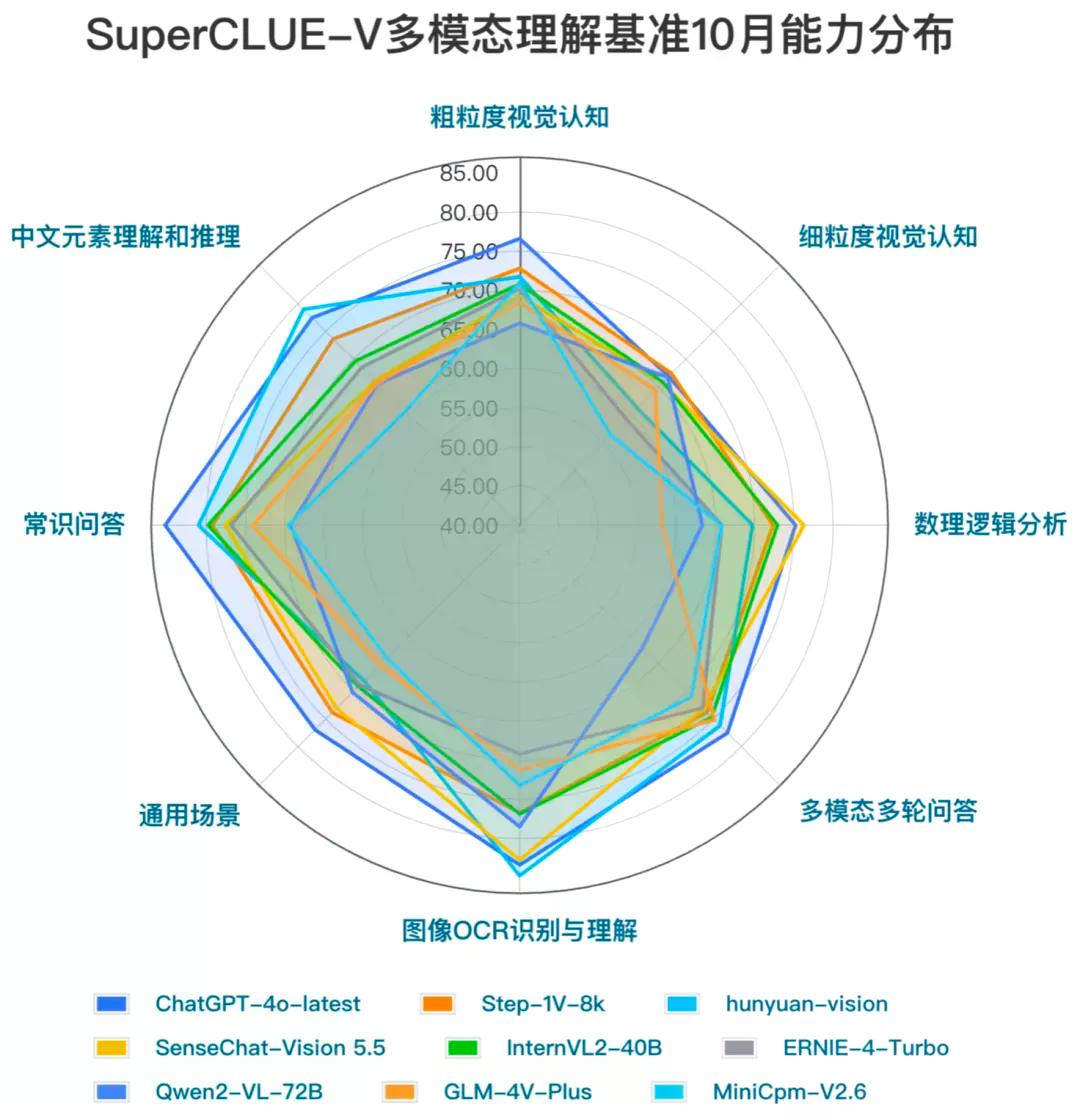
另一方面,国内的多模态大模型在一些特定的细分任务上展现了领先优势。例如,Step-1V-8k在细粒度视觉认知任务中,如特征定位和对象计数方面,表现出了优异的性能,国内模型在处理细节丰富的视觉信息和进行精确的视觉认知方面具有较强的能力。同样,hunyuan-vision在中文元素理解和推理任务中也展现了出色的表现,甚至在某些方面超过了ChatGPT-4o-latest,在处理中文语境下的任务时,国内模型具有独特优势。
然而,报告也指出了国内大模型在基础多模态认知能力上存在提升空间。基础认知能力是指模型对基本多模态信息的理解和处理能力,这是进行更复杂任务的基石。国内外头部多模态大模型在这一能力上的差距为2.47分,意味着在更广泛的多模态认知任务上,国内大模型仍需进一步提升其基础能力,以实现更全面和均衡的性能表现。
在模型对比案例中,可以看到不同模型在不同任务上的表现差异。例如,在细粒度视觉认知任务上,Step-1V-8k和Qwen2-VL-72B表现出色;而在数理逻辑推理任务上,SenseChat-Vision 5.5展现了领先优势。此外,为了确保自动化测评的科学性,SuperCLUE团队还进行了人类一致性评估,结果显示自动化评价具有较高的可靠性,平均合格率达到了96.87%。
 豫公网安备41010702003375号
豫公网安备41010702003375号