
重振流式强化学习研究!阿尔伯塔大学推出stream-x算法族,有效克服了“流式障碍”
![]() 前沿资讯
1729490970更新
前沿资讯
1729490970更新
![]() 0
0
在人类和动物的自然智能中,学习是一个连续的、实时的过程,这涉及到感知环境、采取行动以及从这些行动中学习,而所有这些活动都是无需存储历史经验的。这种流式的学习方式对于资源受限、通信能力有限或对隐私敏感的应用场景特别有价值,因为它不需要保留和处理大量过往的数据。自然的,我们希望在深度强化学习领域能够模仿这种高效的流式学习方式,但现实情况却是,许多现代深度强化学习方法在样本效率方面表现良好,它们在实际应用中却经常面临频繁的不稳定性和学习失败的问题,也被称为“流式障碍”。

▲ arXiv:2410.14606v1
流式障碍的出现主要是因为深度学习模型在处理流式数据时,代理需要即时更新其策略和价值函数,而不依赖于存储过去的经验,这种即时更新的需求使得模型在面对非独立同分布的数据时,容易受到样本之间的干扰,从而导致学习过程的不稳定性。具体而言,代理在每个时间步骤中接收到的新样本可能会与之前的样本有显著差异,这种差异会导致模型的更新方向不一致,进而引发学习失败。
此外,流式学习环境中的数据分布通常是动态变化的,代理需要不断适应这些变化,而这又增加了学习的不确定性。当代理在面对快速变化的环境时,模型的参数可能会频繁波动,导致性能下降,甚至完全失去学习能力。这种不稳定性不仅影响了代理的学习效率,还使得在实际应用中实现稳定的学习变得更加困难。这种障碍的存在,导致了深度强化学习在实际应用中的缺失,尤其是在需要实时决策和资源受限的场合。
为了解决这一挑战,加拿大阿尔伯塔大学计算机科学系研究人员开发了一种新的深度强化学习算法类别,称为stream-x算法。stream-x算法通过一系列创新的技术组合,实现了在流式学习环境中的稳定性和样本效率的提升。这些技术的核心在于稀疏初始化,该技术在神经网络的权重中引入了大量的零值,从而促进了稀疏的权重表示,这种稀疏性减少了不同输入样本之间的干扰,因为只有少数权重会被更新,这样就提高了学习过程的效率。
资格迹的应用是stream-x算法的另一个关键组成部分,它允许算法利用过去的信息来更新价值函数,即使这些过去的样本并没有被实际存储。这种方法模仿了多步返回的优势,即能够考虑更远的未来奖励,而不是仅仅依赖于单步的即时奖励,这使得算法能够在不牺牲流式学习即时更新能力的同时,实现更加有效的学习。
为了维持学习过程的稳定性,stream-x算法采用了一种名为ObGD的优化器。这种优化器通过动态调整步长来控制更新的大小,防止了更新过程中可能出现的过冲或过度校正现象,这种机制确保了即使在面对连续变化的数据流时,学习过程也能保持稳定。数据归一化技术是通过对观测和奖励的统计数据进行计算,并使用这些数据来归一化输入,从而进一步增强了学习的稳定性和效率,这种方法有助于减少不同状态或动作之间由于数值尺度差异而造成的干扰。层归一化技术通过对每一层的预激活输出进行归一化处理,保持了激活分布的稳定性,这对于处理非静态的数据流至关重要,因为它有助于减少由于输入数据的快速变化而导致的学习过程中的不稳定性。stream-x算法族包括流式TD(λ)、流式Q(λ)和流式AC(λ)等算法,它们不依赖于回放缓冲区、批量更新或目标网络,因此非常适合在资源受限的环境中使用。
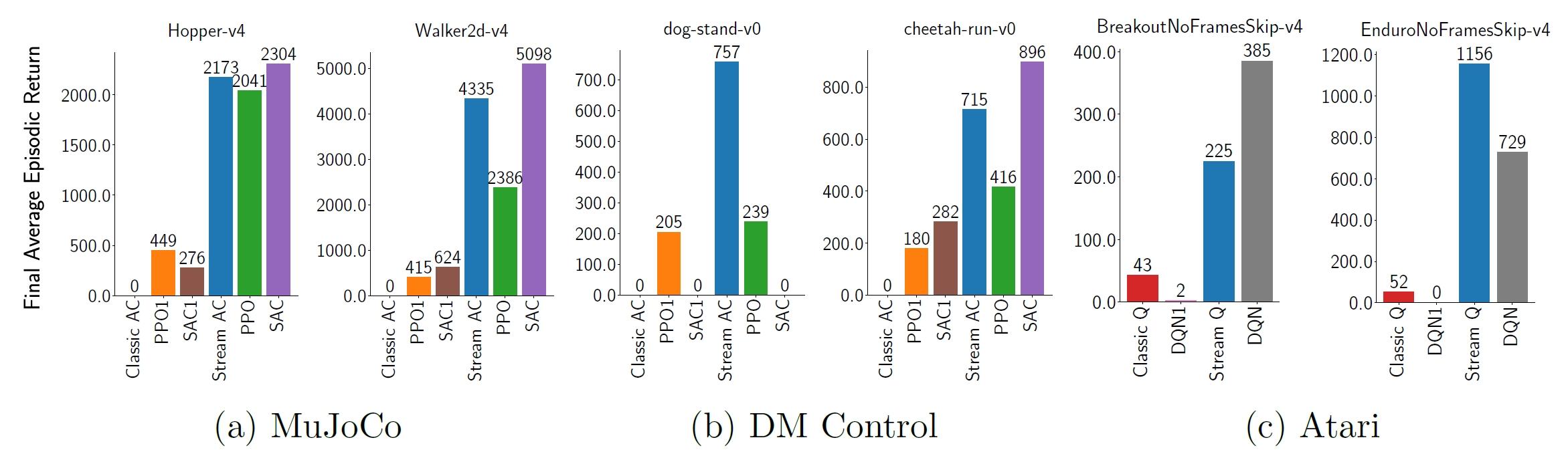
为了验证stream-x算法的有效性,研究人员在Mujoco Gym、DM Control Suite和Atari Games等标准基准测试环境中进行了一系列的实验,这些环境分别代表了不同难度级别的任务。在Mujoco Gym环境中,算法需要控制具有物理属性的机器人手臂或腿,以完成诸如走路、跑步或操纵物体等任务。DM Control Suite提供了更加复杂和真实的物理任务,要求算法在更高级的模拟环境中进行学习。而Atari Games环境则代表了一类具有高维观测空间和复杂动态的任务,算法需要从原始像素中学习如何玩游戏。
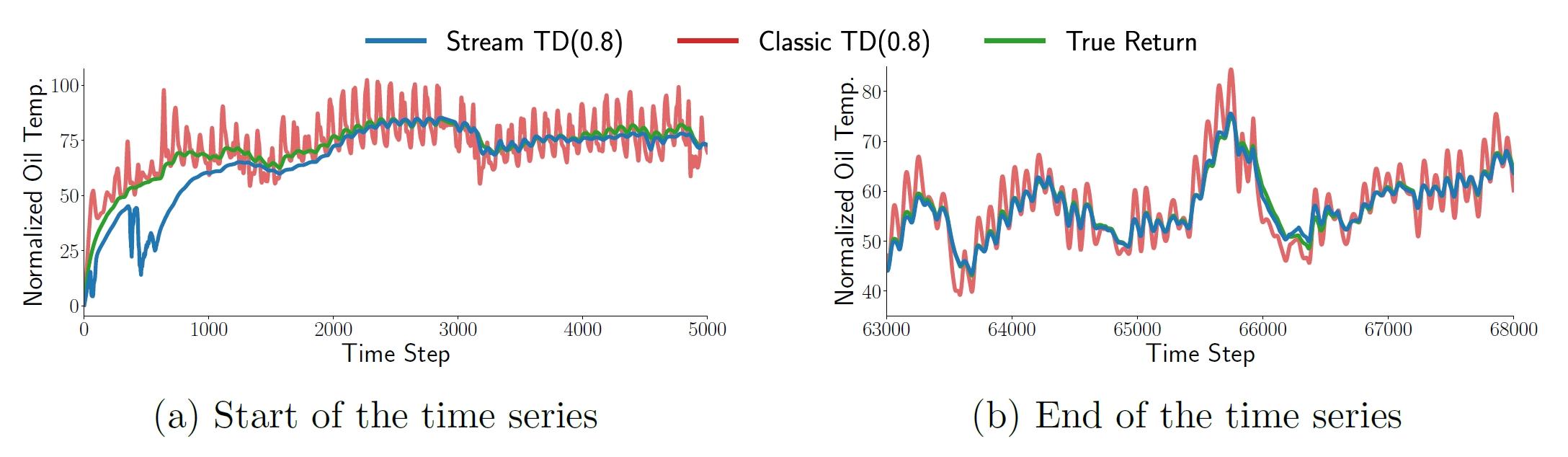
实验中,研究人员首先复现了现有算法在流式学习环境中的不稳定性,这些算法在没有回放缓冲区和批量更新的支持下,通常会出现剧烈的性能波动,甚至完全无法学习。然后,通过应用stream-x算法,包括stream Q、stream AC和stream TD,研究人员成功展示了在相同环境中实现稳定学习的可能性。这些算法通过结合稀疏初始化、资格迹、步长调整策略、数据归一化和层归一化等技术,有效地克服了流式障碍,显示出良好的学习性能和样本效率。
这一成果不仅重振了流式强化学习的研究,也为在资源受限环境中实现深度强化学习提供了可能。通过这些算法,研究人员展示了深度强化学习可以在不依赖于回放缓冲区或批量更新的情况下,有效地处理连续的经验流,这对于推动深度强化学习在更广泛领域的应用具有重要意义。
 豫公网安备41010702003375号
豫公网安备41010702003375号